
Additive & Spectral: Spectral Modeling
McAulay/Quatieri
Sinusoidal modeling can be considered a higher level algorithm for the additive synthesis of harmonic sounds. It has first been used in speech processing by McAulay, R. and Quatieri (1986). For low framerates they proposed a time-domain method for partial synthesis with original phases of the partials.
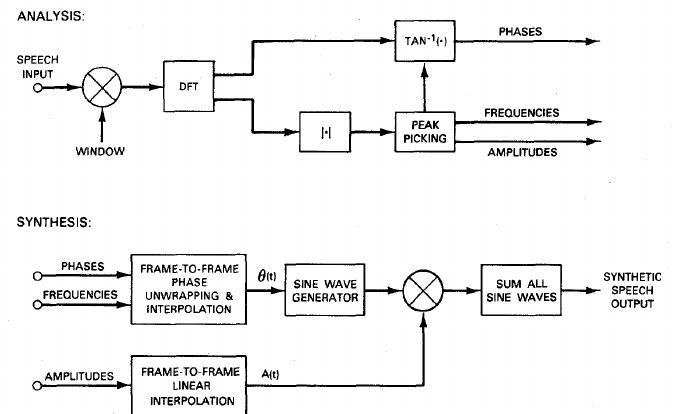
R. McAulay and T. Quatieri (1986)
SMS
The above presented sinusoidal modeling approach captures only the harmonic portion of a sound. With the Sinusoids plus Noise model (SMS), Serra and Smith (1990) introduced the Deterministic + Stochastic model for spectral modeling, in order to model components in the signal which are not captured by partial tracking. A sound is therefor modeled as a combination of a dererministic component - the sinusoids - and a stochasctic component:
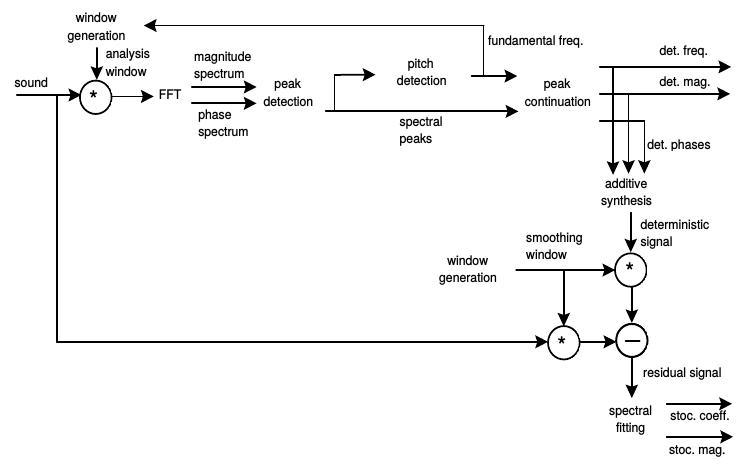
Deterministic + Stochastic model (Serra and Smith, 1990)
Violin Example
The following example shows the sines + noise decomposition for a single violin sound. The original recording was made in an anechoic chamber:
After partial tracking, the deterministic component can be re-synthesized using an oscillator bank. It features the strings oscillation, in this case with original phases. For a bowed string instrument like the violin, the deterministic model alone can deliver plausible results:
The residual signal still carries some parts of the deterministic part, when calculated with simple subtraction. Most of the residual's energy is caused by the bow friction:
Sines + Transients + Noise
Even the harmonic and noise model can not capture all components of musical sounds. The third - and in this line last - signal component to be included are the transients.
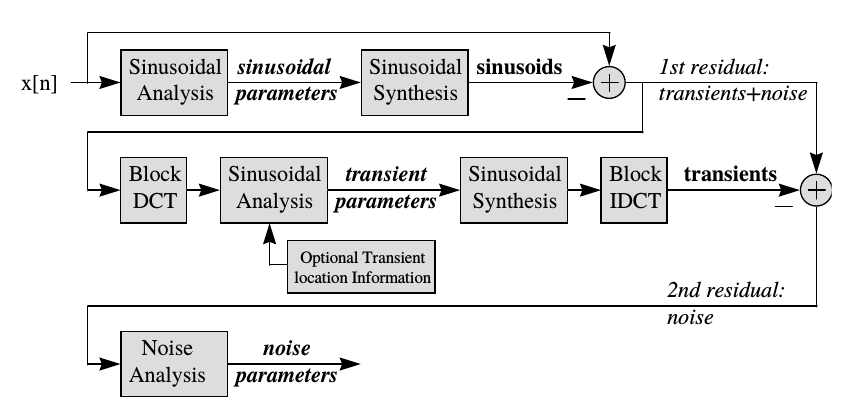
Sines + Transients + Noise (Levine and Smith, 1998)
References
2007
- Arturo Camacho.
Swipe: A Sawtooth Waveform Inspired Pitch Estimator for Speech and Music.
PhD thesis, University of Florida, Gainesville, FL, USA, 2007.
[details] [BibTeX▼]
2005
- Julius O. Smith and Xavier Serra.
PARSHL: An Analysis/Synthesis Program for Non-Harmonic Sounds Based on a Sinusoidal Representation.
In Proceedings of the International Computer Music Conference (ICMC). Barcelona, Spain, 2005.
URL: http://www.bibsonomy.org/bibtex/2fa00c44d6ff2549f4d0559a105631fd7/zazi.
[details] [BibTeX▼]
2002
- Alain de Cheveigné and Hideki Kawahara.
YIN, a Fundamental Frequency Estimator for Speech and Music.
The Journal of the Acoustical Society of America, 111(4):1917–1930, 2002.
[details] [BibTeX▼]
1998
- Scott Levine and Julius Smith.
A Sines + Transients + Noise Audio Representation for Data Compression and Time/Pitch Scale Modifications.
In Proceedings of the 105th Audio Engineering Society Convention. San Francisco, CA, 1998.
[details] [BibTeX▼]
1990
- Xavier Serra and Julius Smith.
Spectral Modeling Synthesis: A Sound Analysis/Synthesis System Based on a Deterministic Plus Stochastic Decomposition .
Computer Music Journal, 14(4):12–14, 1990.
[details] [BibTeX▼]
1986
- R. McAulay and T. Quatieri.
Speech analysis/Synthesis based on a sinusoidal representation.
Acoustics, Speech and Signal Processing, IEEE Transactions on, 34(4):744–754, 1986.
[details] [BibTeX▼] - T Quatieri and Rl McAulay.
Speech transformations based on a sinusoidal representation.
IEEE Transactions on Acoustics, Speech, and Signal Processing, 34(6):1449–1464, 1986.
[details] [BibTeX▼]