
Concatenative: Crowd Noise Synthesis
Two master's thesis in collaboration between Audiocommunication Group and IRCAM aimed at a parametric synthesis of crowd noises, more precisely of many people speaking simultaneously (Grimaldi, 2016; Knörzer, 2017). Using a concatenative approach, the resulting synthesis system can be used to dynamically change the affective state of the virtual crowd. The resulting algorithm was applied in user studies in virtual acoustic environments.
Papers & Thesis:
https://www.atiam.ircam.fr/Archives/Stages1516/GRIMALDI_Vincent_Rapport_Stage.pdf
https://www.static.tu.berlin/fileadmin/www/10002020/Dokumente/Abschlussarbeiten/Knoerzer_MasA.pdf
https://secure.aes.org/forum/pubs/conventions/?elib=18620
Recordings
The corpus of speech was gathered in two group sessions, each with five persons, in the anechoic chamber at TU Berlin. For each speaker, the recording was annotated into regions of different valence and arousal and then segmented into syllables, automatically.
Features
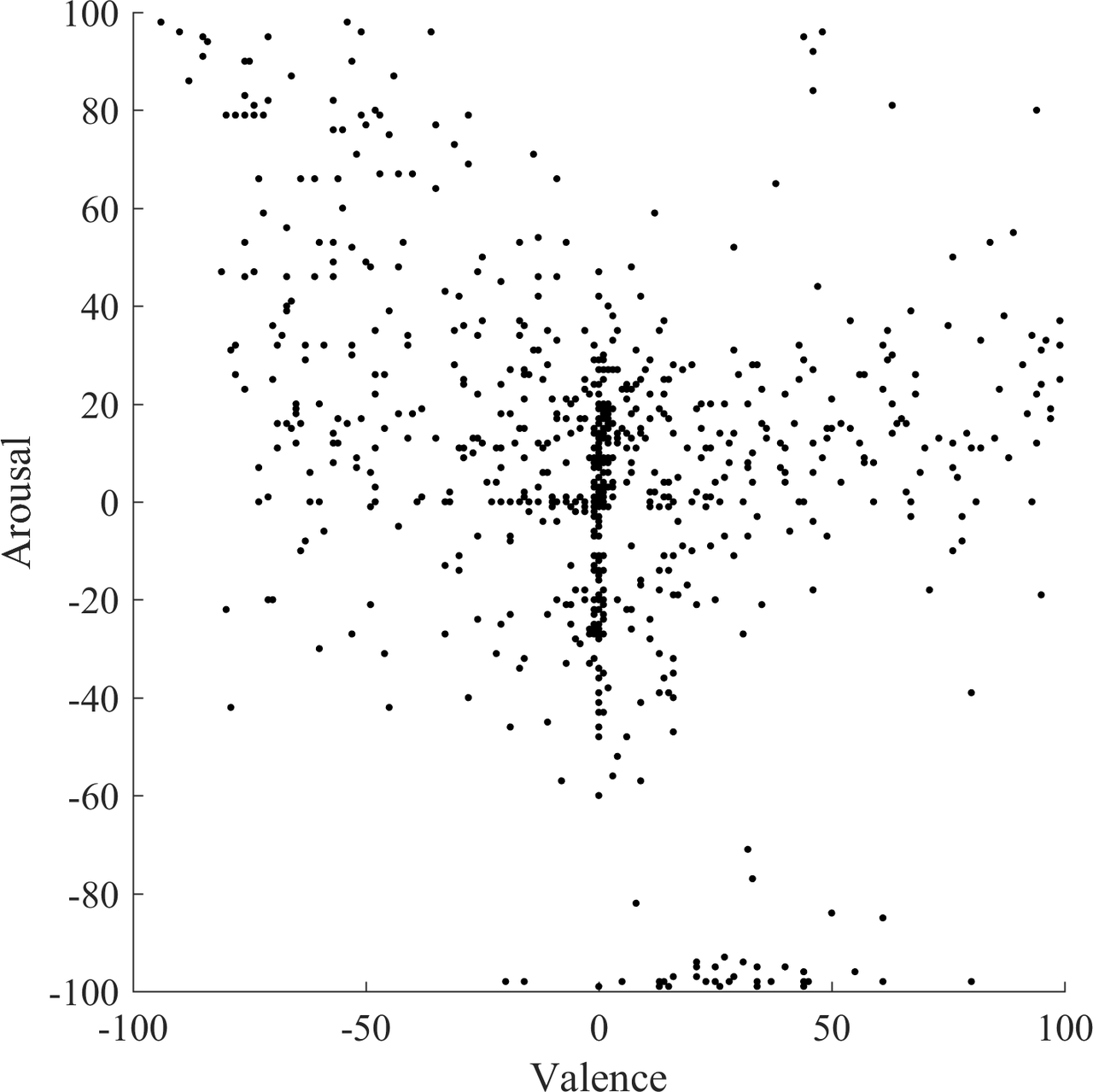
Synthesis
The following example synthesizes a crowd with a valence of -90 and an arousal of 80, which can be categorized as frustrated, annoyed or upset. No virtual acoustic environment is used, and the result is rather direct:
References
2017
-
Grimaldi, Vincent and Böhm, Christoph and Weinzierl, Stefan and von Coler, Henrik.
Parametric Synthesis of Crowd Noises in Virtual Acoustic Environments.
In Proceedings of the 142nd Audio Engineering Society Convention. Audio Engineering Society, 2017.
[details] [BibTeX▼] - Christian Knörzer.
Concatenative crowd noise synthesis.
Master's thesis, TU Berlin, 2017.
[details] [BibTeX▼]
2016
- Vincent Grimaldi.
Parametric crowd synthesis for virtualacoustic environments.
Master's thesis, IRCAM, 2016.
[details] [BibTeX▼]
2006
- Diemo Schwarz.
Concatenative sound synthesis: The early years.
Journal of New Music Research, 35(1):3–22, 2006.
[details] [BibTeX▼] - Diemo Schwarz, Grégory Beller, Bruno Verbrugghe, and Sam Britton.
Real-Time Corpus-Based Concatenative Synthesis with CataRT.
In In DAFx. 2006.
[details] [BibTeX▼]
2000
- Diemo Schwarz.
A System for Data-Driven Concatenative Sound Synthesis.
In Proceedings of the COST-G6 Conference on Digital Audio Effects (DAFx-00). Verona, Italy, 2000.
[details] [BibTeX▼]
1989
- C. Hamon, E. Mouline, and F. Charpentier.
A diphone synthesis system based on time-domain prosodic modifications of speech.
In International Conference on Acoustics, Speech, and Signal Processing,, 238–241 vol.1. May 1989.
doi:10.1109/ICASSP.1989.266409.
[details] [BibTeX▼]
1986
- F. Charpentier and M. Stella.
Diphone synthesis using an overlap-add technique for speech waveforms concatenation.
In ICASSP '86. IEEE International Conference on Acoustics, Speech, and Signal Processing, volume 11, 2015–2018. April 1986.
doi:10.1109/ICASSP.1986.1168657.
[details] [BibTeX▼]