First Sounds with SuperCollider
Boot a Server
Synthesis and processing happens inside an SC server. So the first thing to do when creating sound with SuperCollider is to boot a server. The ScIDE offers menu entries for doing that. However, using code for doing so increases the flexibility. In this first example we will boot the default server. It is per default associated with the global variable s:
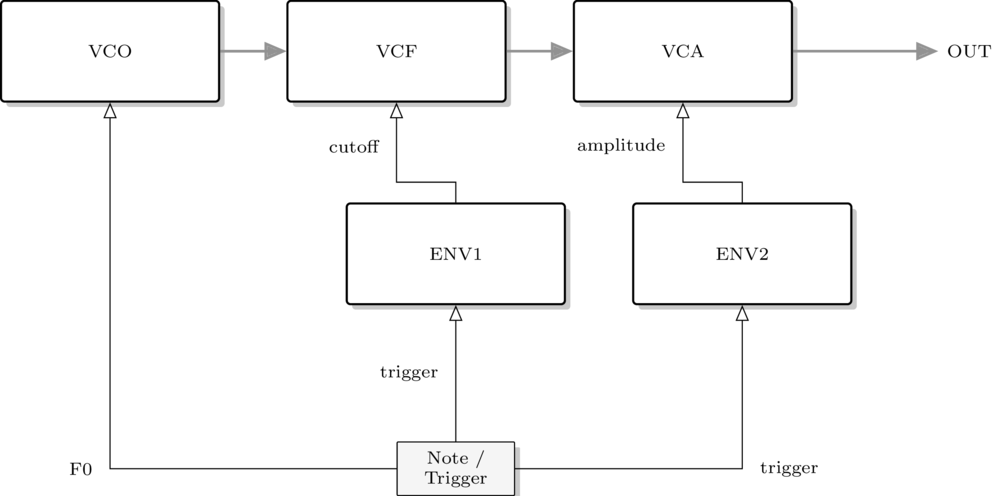
A First Node
In the SC server, sound is generated and processed inside synth nodes. These nodes can later be manipulated, arranged and connected. A simple node can be defined inside a function curly brackets:
UGens
Inside the synth node, the UGen (Unit Generator) SinOsc is used. UGens` are the building blocks
for signal processing on the server. Most ``UGens can be used with audio rate (.ar) or control rate (.kr) (read more on rates and signal types in the section on buses .
In the ScIDE, there are several ways to get information on the active nodes on the SC server. The node tree can be visualized in the server menu options or printed from sclang, by evaluating:
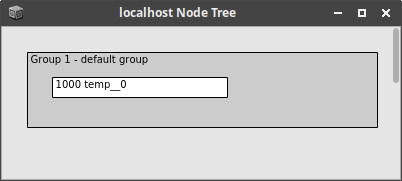
After creating just the sine wave node, the server will show the following node state:
The GUI version of the node tree looks as follows. This representation is updated in real time, when left open:
Removing Nodes
Any node can be removed from a server, provided its unique ID:
All active nodes can be removed from the server at once. This can be very handy when experiments get out of hand or a simple sine wave does not quit. It is done by pressing Shift + . or evaluating:
Running SC Files
SuperCollider code is written in text files with the extensions .sc or .scd. On Linux and Mac systems, a complete SC file can be executed in the terminal by calling the language with the file as argument:
$ sclang sine-example.sc
The program will then run in the terminal and still launch the included GUI elements.